
[1] 0.8413447Random Variables and Probability Distributions
September 3, 2025
Basic Concepts About Random Variables
- Definition of a random variable
- Distributions of random variables
- Properties of operations on random variables
- expectation
- (co)variance
- standard deviation
Definition of a Random Variable
A random variable (RV) is a function that maps each event in a sample space \(\Omega\) to a number (e.g., in \(\R\)), i.e., \(X: \Omega \to \R\)
A discrete random variable takes on a finite number of values.
- Suppose \(X\) is the number of heads in 3 tosses of a fair coin.
- \(x\), a realization of \(X\), can take on the values 0, 1, 2, 3.
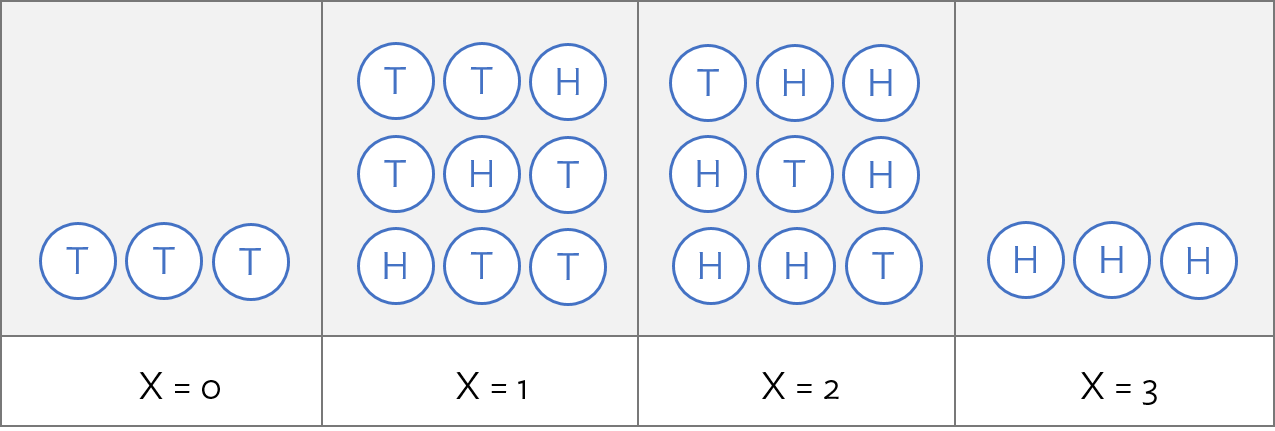
Distribution of a Discrete Random Variable
The distribution of a discrete RV is the collection of its values and the probabilities associated with those values.
The probability distribution for \(X\) is as follows:
| \(x_i\) | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| \(\Pr(X = x_i)\) | 1/8 | 3/8 | 3/8 | 1/8 |
For the distribution to be well-defined, we need that \[\sum_{x=0}^3 \Pr(X = x_i) = 1\]
Example Discrete Distribution of \(X\)
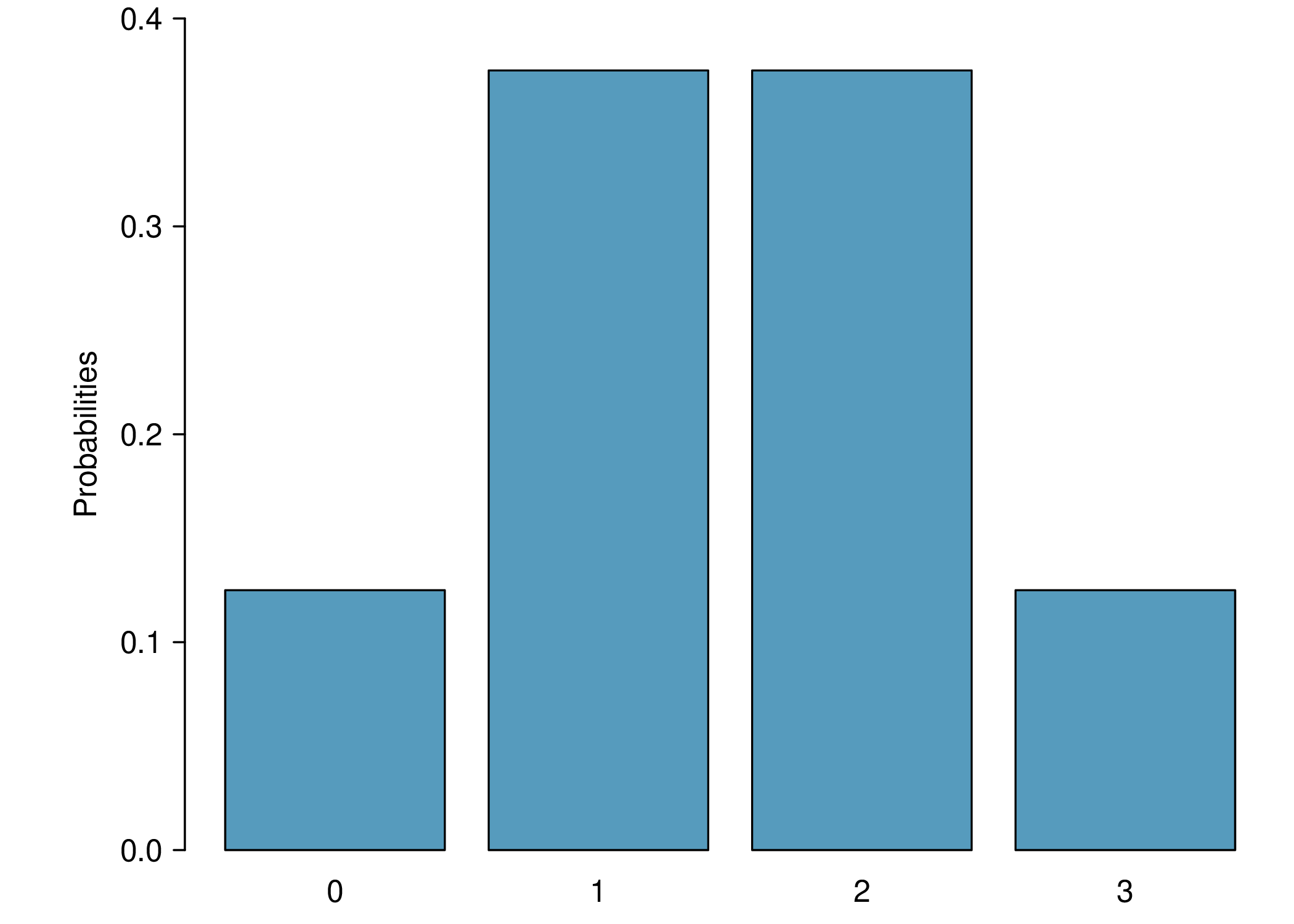
Expectation of a Random Variable
Let \(x_1, \ldots, x_k\) be realizations of \(X\) w/ corresponding probabilities \(\Pr(X=x_1), \ldots, \Pr(X=x_k)\), the expected value of \(X\) is the sum of each multiplied by its corresponding probability:
\[ \E(X) = x_1 \Pr(X=x_1) + \ldots + x_k \Pr(X=x_k) = \sum_{i=1}^{k}x_i \Pr(X=x_i) \]
Sometimes, \(\mu\) may be used in place of the notation \(\E(X)\) and may be written \(\mu_X\).
Calculating an Expectation
Returning to our coin tossing example,
\[\begin{align*} \E(X) &= 0 \Pr(X=0) + 1 \Pr(X=1) + 2 \Pr(X=2) + 3 \Pr(X = 3) \\ &= (0)(1/8) + (1)(3/8) + (2)(3/8) + (3)(1/8) \\ &= 12/8 \\ &= 1.5 \end{align*}\]
Linearity of Expectation
The expectation operator \(\E(X)\) is linear in that:
- \(\E(a \cdot X) = a \cdot \E(X)\), for a constant \(a\)
- \(\E(X + b) = \E(X) + b\), for a constant \(b\)
This turns out to be a very useful property. Intuitively, this follows from the expectation being summation (or integration) operation.
Variance of a Random Variable
Let \(x_1, \ldots, x_k\) be realizations of \(X\) w/ corresponding probabilities \(\Pr(X=x_1), \ldots, \Pr(X=x_k)\) and expected value \(\mu = \E(X)\), then the variance of \(X\), \(\text{Var}(X)\) (or \(\sigma^2_X\))1, is \[\begin{align*} \text{Var}(X) &= (x_1-\mu)^2 \Pr(X=x_1) + \ldots + (x_k-\mu)^2 \Pr(X=x_k) \\ &= \sum_{j=1}^{k} (x_j - \mu)^2 \Pr(X=x_j) \end{align*}\] The standard deviation of \(X\), written \(\text{SD}(X)\) (or \(\sigma_X\)), is just the square root of the variance.
Calculating the Variance of a Random Variable
Again returning to our coin tossing example,
\[\begin{align*} \sigma_X^2 &= (x_1-\mu_X)^2 \Pr(X=x_1) + \cdots+ (x_4-\mu)^2 \Pr(X=x_4) \\ &= (0 - 1.5)^2(1/8) + (1 - 1.5)^2 (3/8)\\ &\mspace{20mu} + (2 - 1.5)^2 (3/8) + (3 - 1.5)^2 (1/8) \\ &= 3/4 \notag \end{align*}\]
The standard deviation is \(\sqrt{3/4} = \sqrt{3}/2 =\) 0.866.
Variance and Expectation
Note that \(\text{Var}(X)\) is the expected squared distance1 of a given realization \(x\) from the RV \(X\)’s expected value \(\E[X]\), so \[\begin{align*} \text{Var}(X) &= \E[(X - \E[X])^2] \\ &= \cdots \\ &= \E[X^2] - \E[X]^2 \end{align*}\]
As noted before, if we define \(\tilde{X} \coloneqq X - \E(X)\), then we have \[\text{Var}(\tilde{X}) = \E(\tilde{X}^2)\]
Covariance of Two Random Variables
For two RVs, \(X\) and \(Y\), their covariance1, \(\text{Cov}(X,Y)\), measures the degree to which the two RVs vary together \[\begin{align*} \text{Cov}(X, Y) &= \E[(X - \E[X]) (Y - \E[Y])] \\ &= \cdots \\ &= \E[X Y] - \E[X] \E[Y] \end{align*}\]
The covariance is tied to another notion—correlation, which we will discuss later in a module on regression analysis.
Binomial Random Variables
A specific type of discrete RV is a binomial RV.
\(X\) is a binomial RV when it represents the number of successes in \(n\) independent replications1 of an experiment where
- Each replicate has two possible outcomes: success or failure
- The probability of success \(p\) in each replicate is constant
Binomial Random Variables
A binomial RV takes on values \(0, 1, 2, \ldots, n\). We use the shorthand \(X \sim \text{Bin}(n,p)\) to say that \(X\) follows a binomial distribution with \(n\) trials and \(p\) success probability.
For example, the number of heads in 3 tosses of a fair coin is a binomial RV with parameters \(n = 3\) and \(p = 0.5\).
For a binomial RV \(X \sim \text{Bin}(n,p)\) with parameters \(n\) and \(p\),
- \(\E[X] = np\)
- \(\text{Var}(X) = n p (1 - p)\)
The Binomial Coefficient
The binomial coefficient \(\binom{n}{x}\) is the number of ways to choose \(x\) items from a set of size \(n\), where the order of the choice is ignored.
Mathematically, \(\binom{n} {x} = \frac{n!}{x!(n-x)!}\)
- \(n = 1, 2, \ldots\)
- \(x = 0, 1, 2, \ldots, n\)
- For any integer \(m\), \(m! = (m)(m-1)(m-2)\ldots(1)\)
Formula for the Binomial Distribution
Let \(x\) be the number of successes in \(n\) trials, then \[\Pr(x \text{ successes}) = \binom{\text{# trials}} {\text{# successes}} p^{\text{# successes}}(1-p)^{\text{# trials - # successes}}\]
\[\Pr(X = x) = \binom{n}{x} p^x (1-p)^{n-x},\: x= 0, 1, 2, \dots, n\] Parameters of the distribution:
- \(n\) = number of trials
- \(p\) = probability of success
Calculating Binomial Probabilities in R
The function dbinom() is used to calculate \(\Pr(X = k)\).
dbinom(k, n, p): \(\Pr(X = k)\)
The function pbinom() is used to calculate \(\Pr(X \leq k)\) or \(\Pr(X > k)\).
pbinom(k, n, p): \(\Pr(X \leq k)\)pbinom(k, n, p, lower.tail = FALSE): \(\Pr(X > k)\)
Continuous Random Variables
A discrete random variable takes on a finite number of values.
- Number of heads in a \(n\) coin tosses
- Number of people who’ve had chicken pox in a random sample
A continuous random variable takes on any value in an interval.
- Height in a population
- Blood pressure in a population
Discrete RVs are counted, continuous RVs are measured.
Probabilities from Continuous Distributions
Two important features of continuous distributions:
- The total area under the density curve is 1.
- The probability that a variable has a value within a specified interval is the area under the curve over that interval.
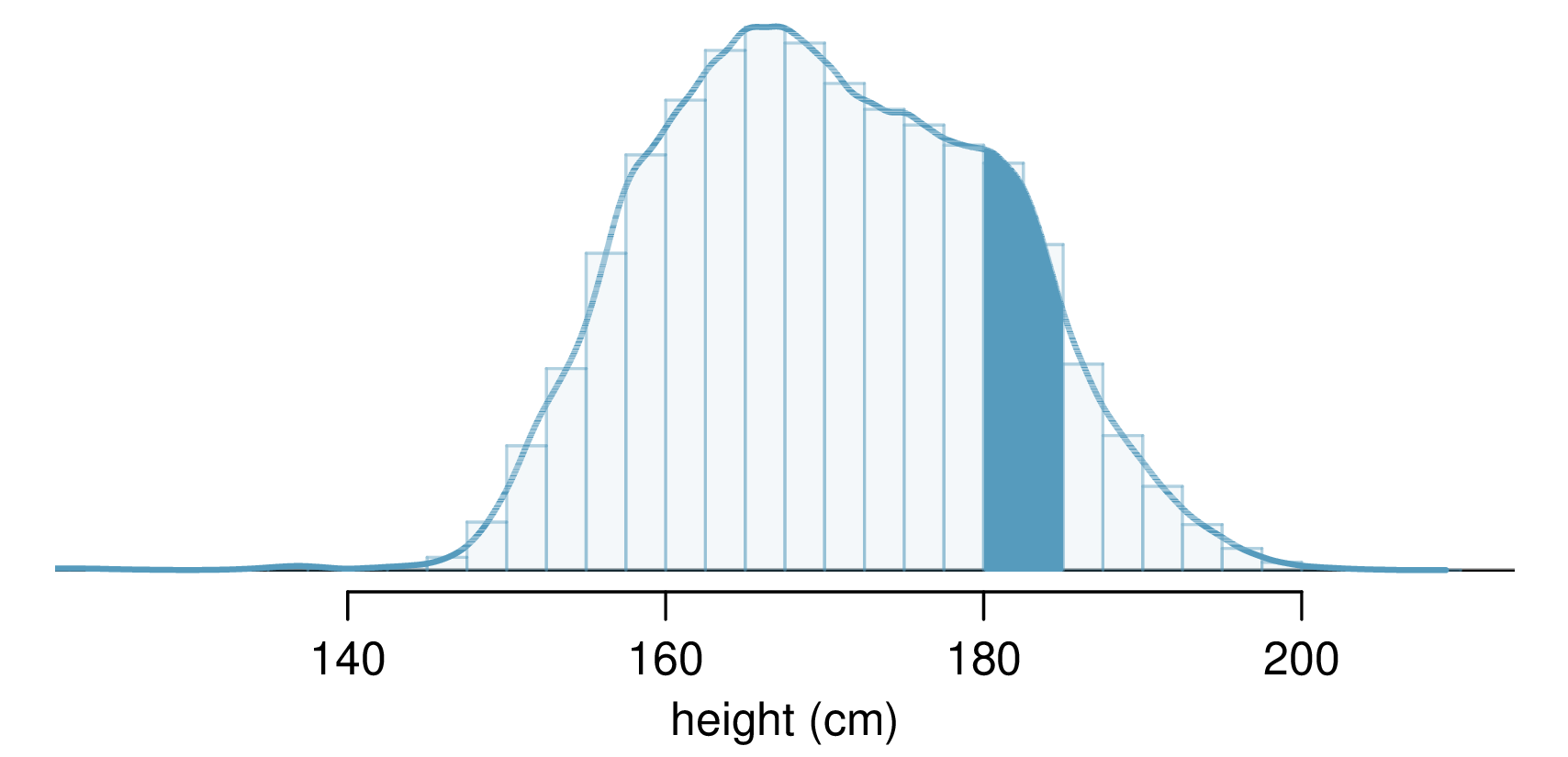
Probabilities from Continuous Distributions
When working with continuous random variables, probability is found for intervals of values rather than individual values.
- Formally, the probability that a continuous RV \(X\) takes on any single individual value is zero, that is, \(\Pr(X = x) = 0\)1.
- Thus, \(\Pr(a < X < b)\) is equivalent to \(\Pr(a \leq X \leq b)\).
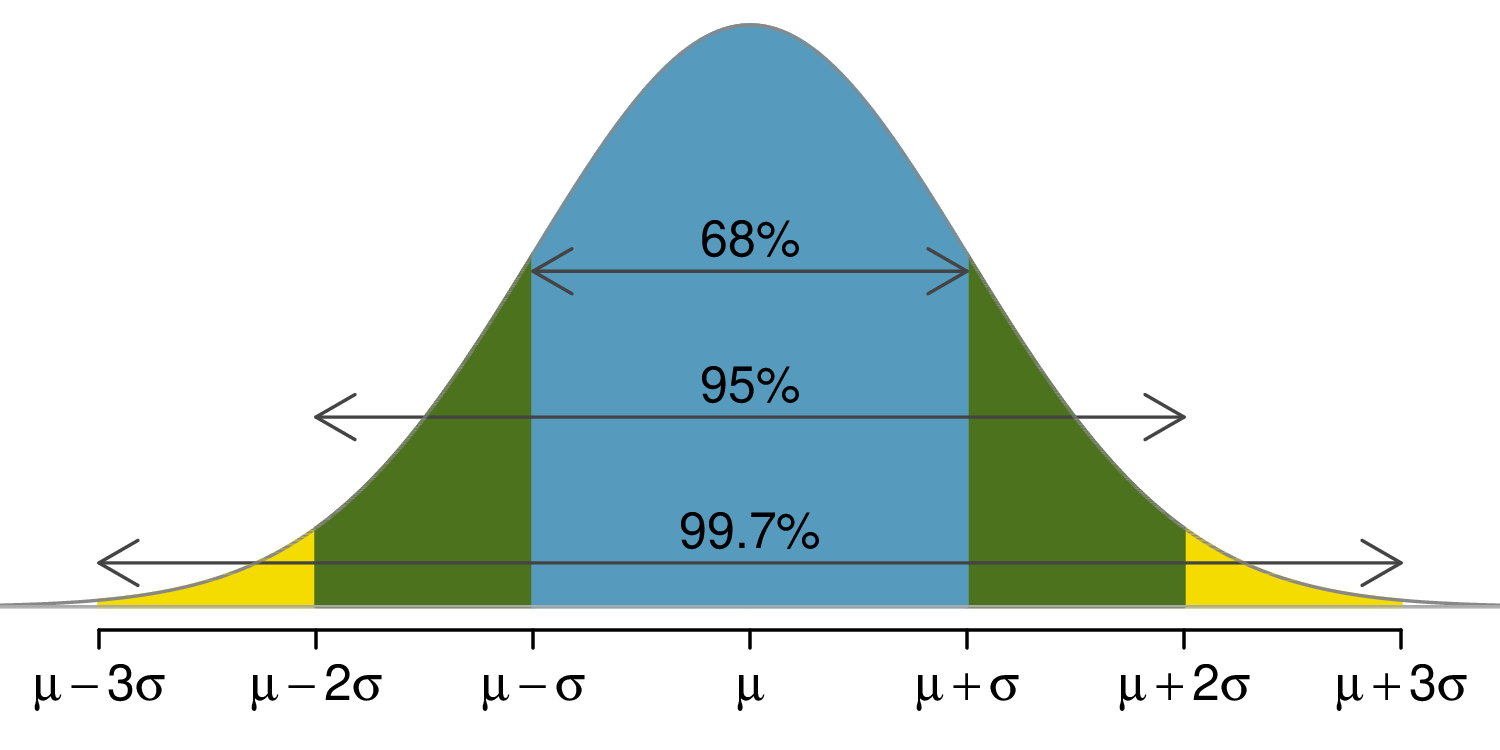
The “Empirical Rule” for the Normal Distribution
According to the “empirical rule,” for any1 normal distribution,
- approximately 68% of the data are within 1 SD of the mean
- approximately 95% of the data are within 2 SDs of the mean
- approximately 99.7% of the data are within 3 SDs of the mean
The “Empirical Rule” for the Normal Distribution
An Example of Using a Normal Distribution
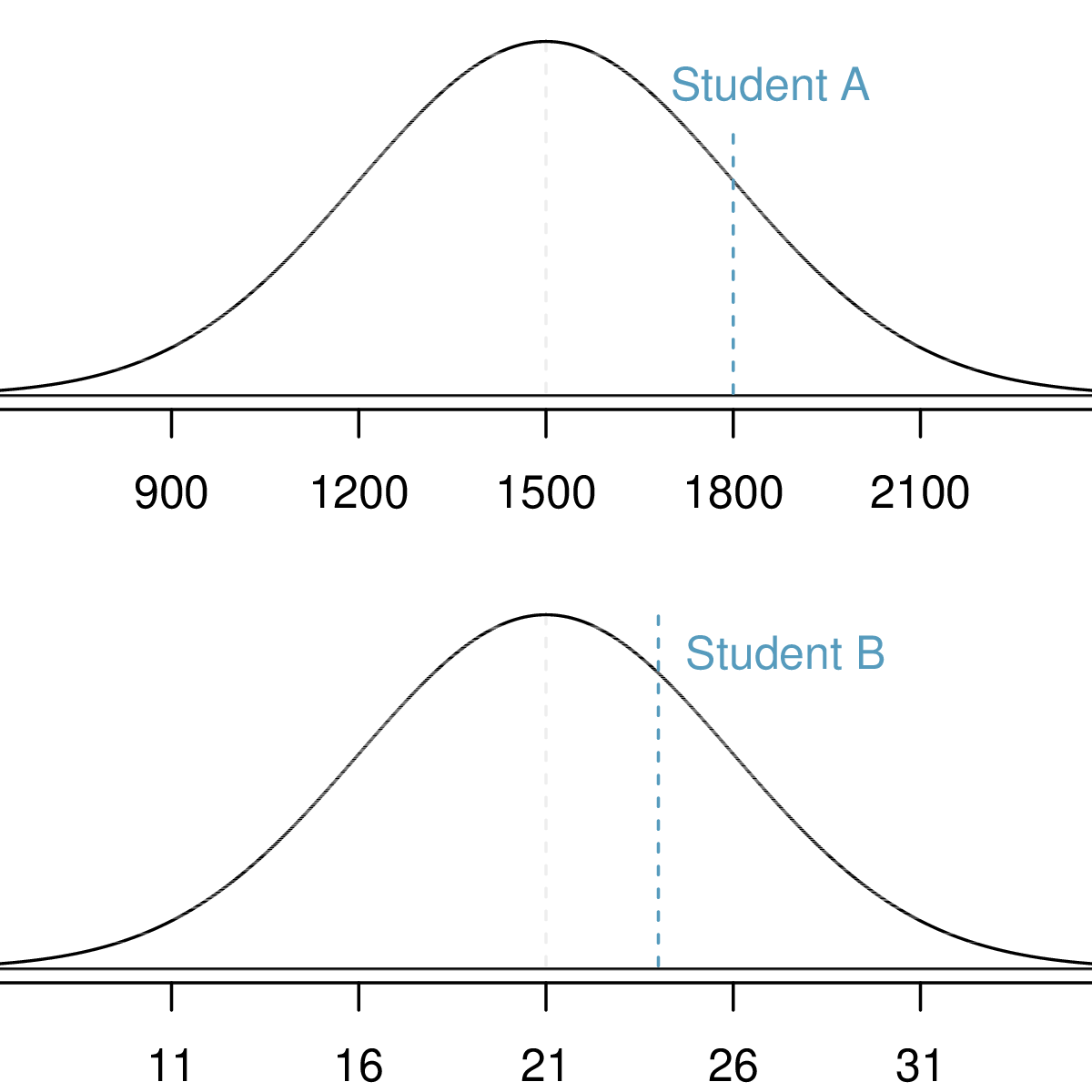
Assume that the distributions of test scores on the SAT and ACT are normal with means \(\mu_{\text{SAT}}\), \(\mu_{\text{ACT}}\) and variances \(\sigma^2_{\text{SAT}}\), \(\sigma^2_{\text{ACT}}\).
Suppose that one student scores an 1800 on the SAT (Student A) and another student scores a 24 on the ACT (Student B). Which student performed better?
Standard Normal Distribution
A standard normal distribution is defined as a normal distribution with mean 0 and variance 1. It is often denoted as \(Z \sim \text{N}(0, 1)\).
Any normal random variable \(X\) can be transformed into a standard normal random variable \(Z\).
\[Z = \dfrac{X - \mu}{\sigma} \qquad X = \mu + Z\sigma\]
Example of Using a Normal Distribution
- SAT scores are \(\text{N}(1500, 300)\); ACT scores are \(\text{N}(21, 5)\).
- \(x_A\) is the score of Student A; \(x_B\) is the score of Student B.
\[Z_{A} = \frac{x_{A} - \mu_{SAT}}{\sigma_{SAT}} = \frac{1800-1500}{300} = 1\]
\[Z_{B} = \frac{x_{B} - \mu_{ACT}}{\sigma_{ACT}} = \frac{24 - 21}{5} = 0.6\]
Calculating Probabilities from Normal Distributions
What is the percentile rank for a student who scores an 1800 on the SAT for a year in which the scores are \(\text{N}(1500, 300)\)?
Calculate a \(Z\)-score. If \(X \sim \text{N}(\mu, \sigma^2)\), \(Z = \frac{X - \mu}{\sigma} \sim \text{N}(0, 1)\)
pnorm(z)gives the area (i.e., probability) to the left of \(z\)Alternatively, let
Rdo the work…
Calculating Probabilities from Normal Distributions
What score on the SAT would put a student in the 99th percentile?
Identify the \(Z\)-value.
qnorm(p)calculates the value \(z\) (a quantile) such that for a \(Z \sim \text{N}(0, 1)\), \(p = \Pr(Z \leq z)\).If \(Z \sim \text{N}(0, 1)\), then \(X = \sigma Z + \mu\), and \(X \sim \text{N}(\mu, \sigma^2)\), so \[X = \sigma Z + \mu = 300(2.33) + 1500 = 2199\]
Alternatively, let
Rdo the work …
Words of Warning…
“Everyone is sure of this [that errors are normally distributed]…since the experimentalists believe that it is a mathematical theorem, and the mathematicians that it is an experimentally determined fact.” –Poincaré (1912)
“Far better an approximate answer to the right question, which is often vague, than the exact answer to the wrong question, which can always be made precise.” –Tukey (1962)
The Poisson Distribution
The Poisson distribution is used to calculate probabilities for rare events that accumulate over time (but is often used for counts).
It used most often in settings where events happen at a rate \(\lambda\) per unit of population and per unit time, such as the annual incidence of a disease in a population.
- Typical example: for children ages 0-14, the incidence rate of acute lymphocytic leukemia (ALL) was about 30 diagnosed cases per million children per year in the decade 2000-2010.
- Always important to note and understand the units.
Example: Outbreaks of Childhood Leukemia
Fortunately, childhood cancers are rare.
For children ages 0-14, the incidence rate of acute lymphocytic leukemia (ALL) was approximately 30 diagnosed cases per million children per year in the decade from 2000-2010. Given that about 20% of the US population are in this age range, we may ask
- What is the incidence rate of ALL over a 5 year period?
- In a small city of 75,000 people, what is the probability of observing exactly 8 cases of ALL over a 5 year period?
- In the small city, what is the probability of observing 8 or more cases of ALL over a 5 year period?
Poisson Distribution
Suppose events occur over a fixed time window in such a way that
- The probability an event occurs in an interval is proportional to the length of the interval.
- Events occur independently at a rate \(\lambda\) per unit of time.
Poisson Distribution
Then the probability of exactly \(x\) events in one unit of time is \[ \Pr(X = x) = \frac{e^{-\lambda} \lambda^{x}}{x!}, \,\, x = 0, 1, 2, \ldots \]
- The mean is \(\lambda\), i.e., \(\E[X] = \lambda\).
- The standard deviation is \(\sqrt{\lambda}\), i.e., \(\text{Var}(X) = \lambda\).
Poisson Distribution
The probability of exactly \(x\) events \(t\) units of time is \[\Pr(X = x) = \frac{e^{-\lambda t}(\lambda t)^{x}}{x!}, \,\, x = 0, 1, 2, \ldots\]
- The mean is \(\lambda t\), i.e., \(\E[X] = \lambda t\).
- The standard deviation is \(\sqrt{\lambda t}\), i.e., \(\text{Var}(X) = \lambda t\).
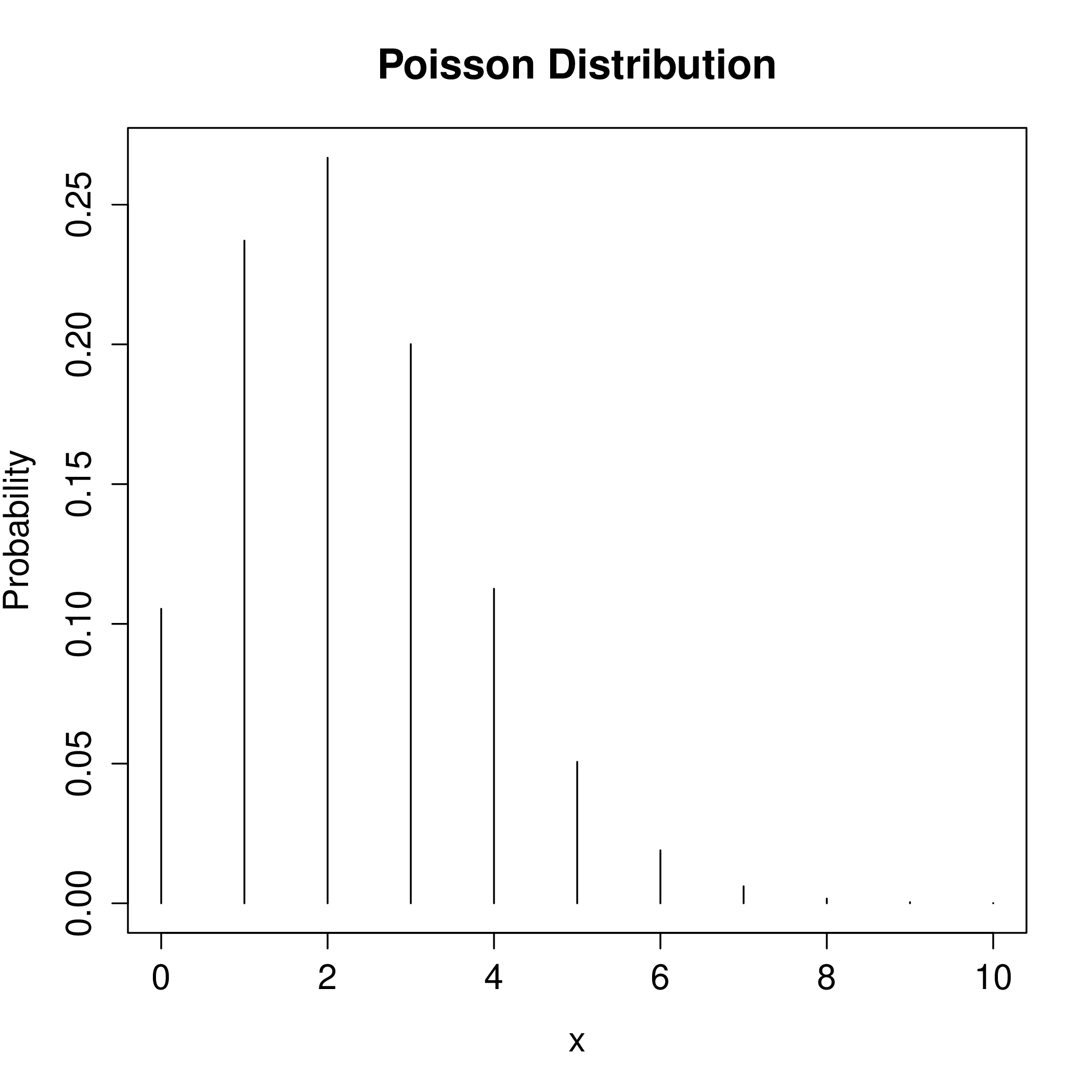
Poisson Distribution with \(\lambda = 2.25\)
Childhood Leukemia Incidence
See Example 3.37 of Vu and Harrington (2020) for details.
What is the incidence rate of ALL over a 5 year period?
Incidence rate of ALL in a year is 30 cases per 1,000,000 children: \[\dfrac{30}{1,000,000}= 0.00003 = 3\times 10^{-5}\]
Incidence rate in a 5-year period is (5)(30) per 1,000,000 children: \[\dfrac{150}{1,000,000} = 0.00015 = 1.5 \times 10^{-4}\]
…and what about a city of size 75,000?
In a small city of 75,000 people, what is the probability of observing exactly 8 cases of ALL over a 5 year period?
In a city of 75,000 people, about \((75,000)(0.20) = 15,000\) children will be age 0-14.
The five-year rate of new cases for the whole city would be
\[(1.5 \times 10^{-4})(15,000) = 2.25\]
What is the probability of 8 cases over 5 years?
In a small city, what is the probability of observing 8 or more ALL cases in a 5-year period?
\[ \Pr(X=8) = \frac{e^{-\lambda}\lambda^{x}}{x!} = \frac{e^{(-2.25)}(2.25)^{8}}{8!} \]
Easiest to calculate this in R. To do so, suppose \(X \sim
\text{Pois}(\lambda)\), then dpois(k, lambda) gives \(\Pr(X = k)\)
…but what is the probability of 8 or more cases?
In a small city, what is the probability of observing 8 or more ALL cases in a 5 year period?
Would 8 or more cases be a rare event? Suppose \(X \sim \text{Pois}(\lambda)\) and calculate \(\Pr(X \geq 8) = 1 - \Pr(X \leq 7)\).
Compute \(\Pr(X \leq k)\) using ppois(k, lambda)
Or \(\Pr(X > k)\) as ppois(k, lambda, lower.tail = FALSE)
Summary Table of Distributions
| Binomial | Normal | Poisson | |
|---|---|---|---|
| Parameters | \(n\), \(p\) | \(\mu\), \(\sigma\) | \(\lambda\) |
| Possible values | \(0,1,\ldots,n\) | (-\(\infty\), \(\infty\)) | \(0,1,\ldots,\infty\) |
| Mean | \(np\) | \(\mu\) | \(\lambda\) |
| Standard Deviation | \(\sqrt{np(1-p)}\) | \(\sigma\) | \(\sqrt{\lambda}\) |
References
Poincaré, Henri. 1912. Calcul Des Probabilités. Vol. 1. Gauthier-Villars.
Tukey, John W. 1962. “The Future of Data Analysis.” The Annals of Mathematical Statistics 33 (1): 1–67. https://doi.org/10.1214/aoms/1177704711.
Vu, Julie, and David Harrington. 2020. Introductory Statistics for the Life and Biomedical Sciences. OpenIntro. https://openintro.org/book/biostat.

HST 190: Introduction to Biostatistics