
Elements of Statistical Inference, Part I
September 3, 2025
Statistical inference?
Statistics uses tools from probability and data analysis to
- draw inferences about populations from samples
- quantify uncertainty (or confidence) about an inference
We’ll illustrate inferential principles in the setting of
- estimating average characteristics of a well-defined population
- drawing conclusions about that characteristic
Perspectives on statistical inference
Some pithy philosophy on statistics
- Statisticians are “engaged in an exhausting but exhilarating struggle with the biggest challenge that philosophy makes to science: how do we translate information into knowledge?” –Senn (2022)
- “Statistics is the art of making numerical conjectures about puzzling questions.” –Freedman, Pisani, and Purves (2007)
- “Statistics is an area of science concerned with the extraction of information from numerical data and its use in making inferences about a population from which the data are obtained.” –Mendenhall, Beaver, and Beaver (2012)
- “The objective of statistics is to make inferences (predictions, decisions) about a population based on information contained in a sample.” –Mendenhall, Beaver, and Beaver (2012)
Example: The YRBSS survey data
Consider the Youth Risk Factor Behavior Surveillance System (YRBSS), a survey conducted by the CDC to measure health-related activity in high school aged youth. The YRBSS data contain
- 2.6 million high school students, who participated between 1991 and 2013 across more than 1,100 separate surveys.
- Dataset
yrbssin theoibiostatRpackage contains the responses from the 13,583 participants from the year 2013.
The CDC used 13,572 students’ responses to estimate health behaviors in a target population: 21.2 million high school-aged students in US in 2013.
Of populations and parameters
The mean weight among the 21.2 million students is an example of a population parameter, i.e., \(\mu_{\text{weight}}\).
The mean within a sample (e.g., as with the 13,572 students in YRBSS), is a point estimate \(\bar{x}_{\text{weight}}\) of a population parameter.
Estimating the population mean weight from the sample of 13,572 participants is an example of statistical inference.
Why inference? It is too tedious to gather this information for all 21.2 million students—also, it is unnecessary.
Of populations and parameters
In nearly all studies, there is one target population and one sample.
Suppose a different random sample (of the same size) were taken from the same population—different participants, different \(\bar{x}_{\text{weight}}\).
Sampling variability describes the degree to which a point estimate varies from sample to sample (assuming fixed sampling scheme).
Properties of sampling variability (randomness) allow for us to account for its effect on estimates based on a sample.
Sampling from a population
- The exact values of population parameters are unknown.
- To what degree does sampling variability affect \(\bar{x}\) as an estimate of \(\mu\).
- As an example, let the YRBSS data (of 13,572 individuals) be the target population, with mean weight \(\mu_{weight}\).
- Sample from this population (e.g., \(n = 100\)) and calculate \(\bar{x}_{weight}\), the mean weight among the sampled individuals.
- How well does \(\bar{x}_{weight}\) estimate \(\mu_{weight}\)?
- Take many samples to construct the sampling distribution of \(\bar{X}\).
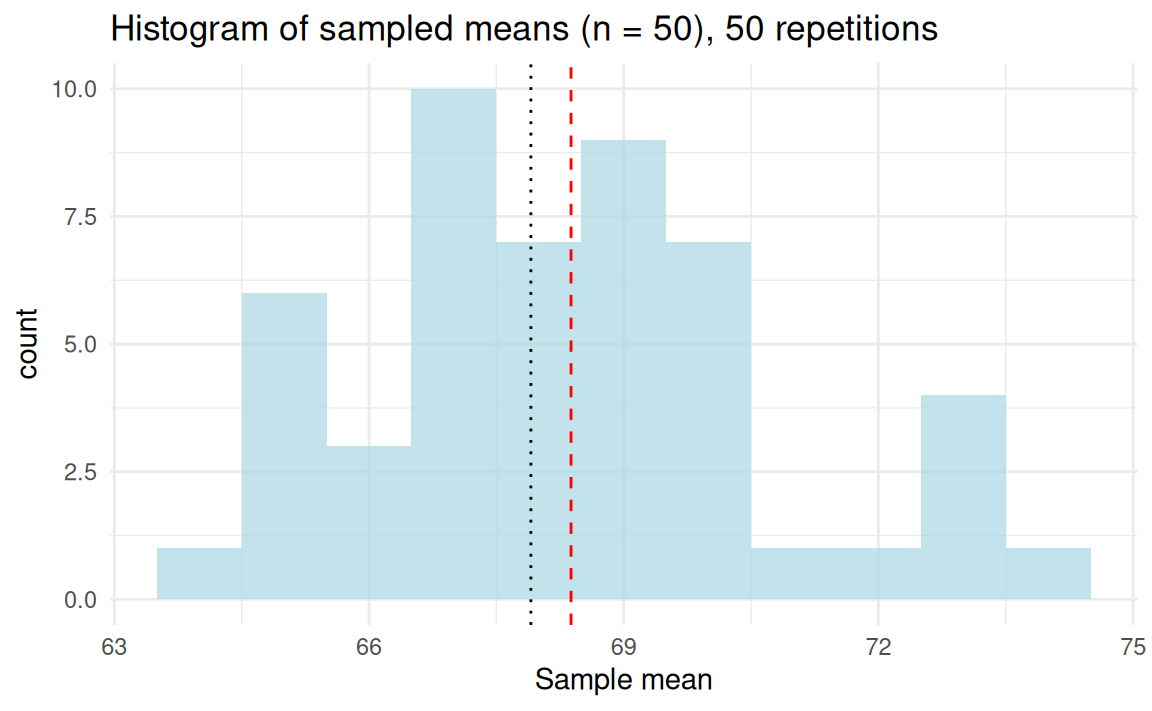
Taking samples from the YRBSS data
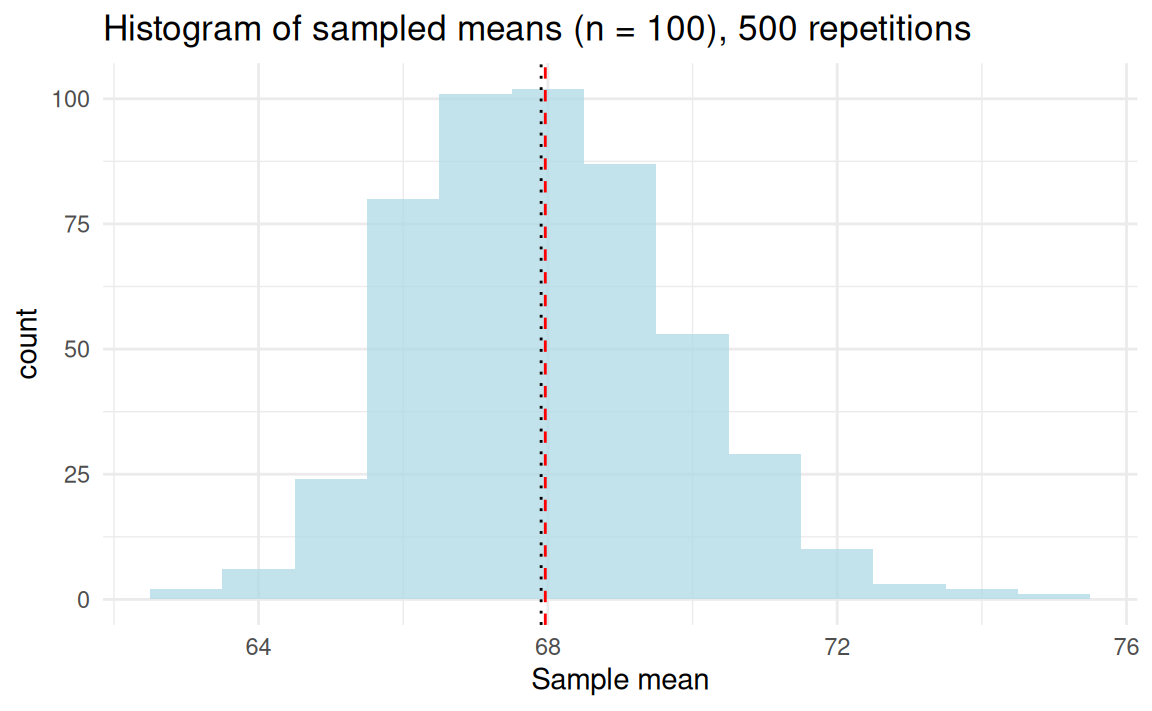
The estimator \(\bar{X}\) is a random variable—randomness from sampling.
The sample mean as a random variable
The statistic \(\bar{X}\) is a random variable for which \(\bar{X} \sim \text{N}(\mu, \sigma^2_{\bar{X}} )\)
- The sampling distribution of \(\bar{X}\) is centered around \(\mu\) because \(\bar{X} \to \mu\) (consistency, strong law of large numbers).
- The variability of \(\bar{X}\) becomes smaller with larger sample size, \(n\).
Any sample statistic is a random variable since each sample drawn from the population ought to be different.
When the data have not yet been observed, the statistic, like the corresponding RV, is a function of the same random elements.
The standard error of \(\bar{X}\)
If \(\bar{X}\) could be observed through repeated sampling, its standard deviation would be \(\text{SE}_{\bar{X}} = \dfrac{\sigma_X}{\sqrt{n}}\) (n.b., \(\text{SE}_{\bar{X}} = \sqrt{\sigma^2_{\bar{X}}}\))
The variability of a sample mean decreases as sample size increases: \(\text{SE}_{\bar{X}}\) characterizes that behavior more precisely.
- Typically, \(\sigma_X\) is unknown and estimated by \(s_X\).
- The term \(\frac{s_X}{\sqrt{n}}\) is called the standard error of \(\bar{X}\).
Leveraging variability: Confidence intervals
A confidence interval gives a plausible range of values for the population parameter, coupling an estimate and a margin of error:
Confidence intervals: Definition and construction
A confidence interval with coverage rate \(1-\alpha\) for a population mean \(\mu\) is any random interval \(\text{CI}_{(1-\alpha)}(\mu)\) such that \(\mathbb{P}[\mu \in \text{CI}_{(1-\alpha)}(\mu)] \geq 1 - \alpha\). A common form is \[\bar{x} \pm m \rightarrow (\bar{x} - m, \bar{x} + m),\] where the margin of error, \(m\), draws on the sampling variability of \(\bar{X}\).
Since \(\sqrt{n}(\bar{X} - \mu) \to_d \text{N}(0, \sigma^2)\), the margin of error may be based on the properties (e.g., quantiles) of the normal distribution.
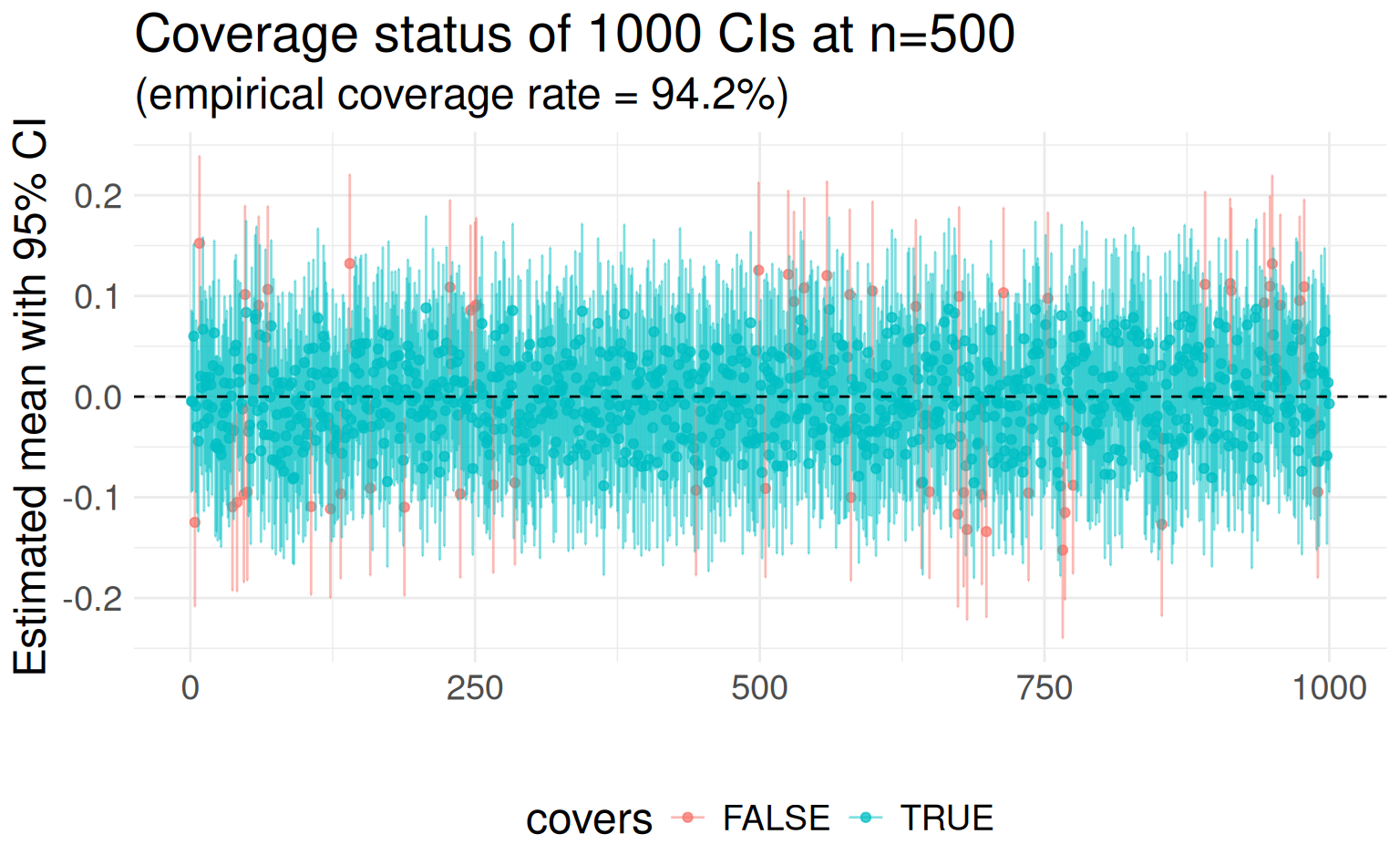
Confidence intervals: The fine print…
The confidence level may also be called the confidence coefficient. Confidence intervals have a nuanced interpretation:
- The method for computing a 95% confidence interval produces a random interval that—on average—contains the true (target) population parameter 95 times out of 100.
- 5 out of 100 will be incorrect, but, of course, a data analyst (or reader of your paper!) cannot know whether a particular interval contains the true population parameter.
- The data used to calculate the confidence interval are from a random sample taken from a well-defined target population.
Confidence intervals: Proof by picture
Asymptotic \(1-\alpha\)(100)% CI
Random interval \(\text{CI}_{(1-\alpha)}(\mu)\) is a \((1-\alpha)\)(100)% CI if \(\lim_{n \to \infty} \mathbb{P}[\mu \in \text{CI}_{(1-\alpha)}(\mu)] \geq 1 - \alpha\)
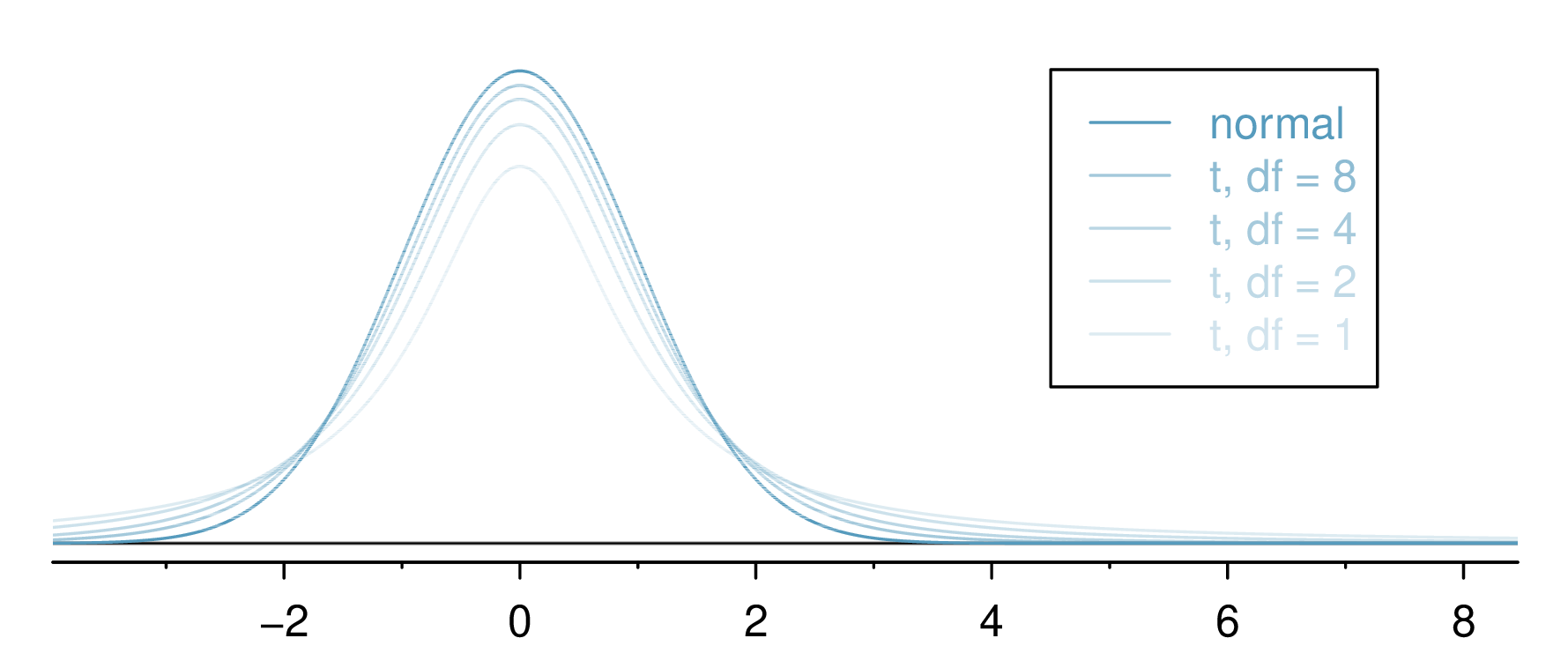
The \(t\) Distribution
The \(t\) distribution1 is symmetric, bell-shaped, and centered at zero; it is like a standard normal distribution \(\text{N}(0,1)\), almost…
It has an additional parameter–degrees of freedom (\(df\) or \(\nu\)).
- Degrees of freedom (\(df\)) equals \(\nu = n - 1\).
- The \(t\) distribution’s tails are thicker than those of a normal.
- When \(df\) is “large” (\(df \geq 30\)), the \(t\) and \(\text{N}(0,1)\) distributions are virtually identical (technically, only when \(\nu \to \infty\)).
The \(t\) Distribution…
A (\(1 - \alpha\))(100)% confidence interval
A (\(1 - \alpha\))(100)% confidence interval (CI) for a population mean \(\mu\) based on a single sample with mean \(\bar{x}\) is
\[\bar{x} \pm t^\star \times \frac{s}{\sqrt{n}} \rightarrow \left( \bar{x} - t^\star\frac{s}{\sqrt{n}},\bar{x} + t^\star\frac{s}{\sqrt{n}} \right),\] where \(t^\star\) is the quantile of a \(t\) distribution (with \(\nu = n-1\) df) for which there is \(1 - \dfrac{\alpha}{2}\) area to its left.
For a 95% CI, find \(t^\star\) with 0.975 area to its left (or, equivalently, 0.025 area to its right).
Calculating the critical \(t\)-value, \(t^\star\)
The R function qt(p, df) finds the quantile of a \(t\) distribution with df degrees of freedom that has area \(p = \mathbb{P}(T \leq t)\) to its left.
\(t^\star\) for a 95% confidence interval where \(n = 10\) is 2.262.
Just let
Rdo the work for you…95% CI fromt.test():
Inference: Testing a hypothesis
Question: Do Americans tend to be overweight?
- Body mass index (BMI) is a scale used to assess weight status, adjusting for height.
- The CDC’s National Health and Nutrition Examination Survey (NHANES) assesses health and nutritional status of adults, children in the US.
| Category | BMI range |
|---|---|
| Underweight | \(<18.50\) |
| Healthy weight | 18.5-24.99 |
| Overweight | \(\geq 25\) |
| Obese | \(\geq30\) |
The NHANES sample
nhanes.samp.adult(from theoibiostatRpackage):- random sample from participants in NHANES in the US
- contains data on participants who were aged 21 or older at time of response
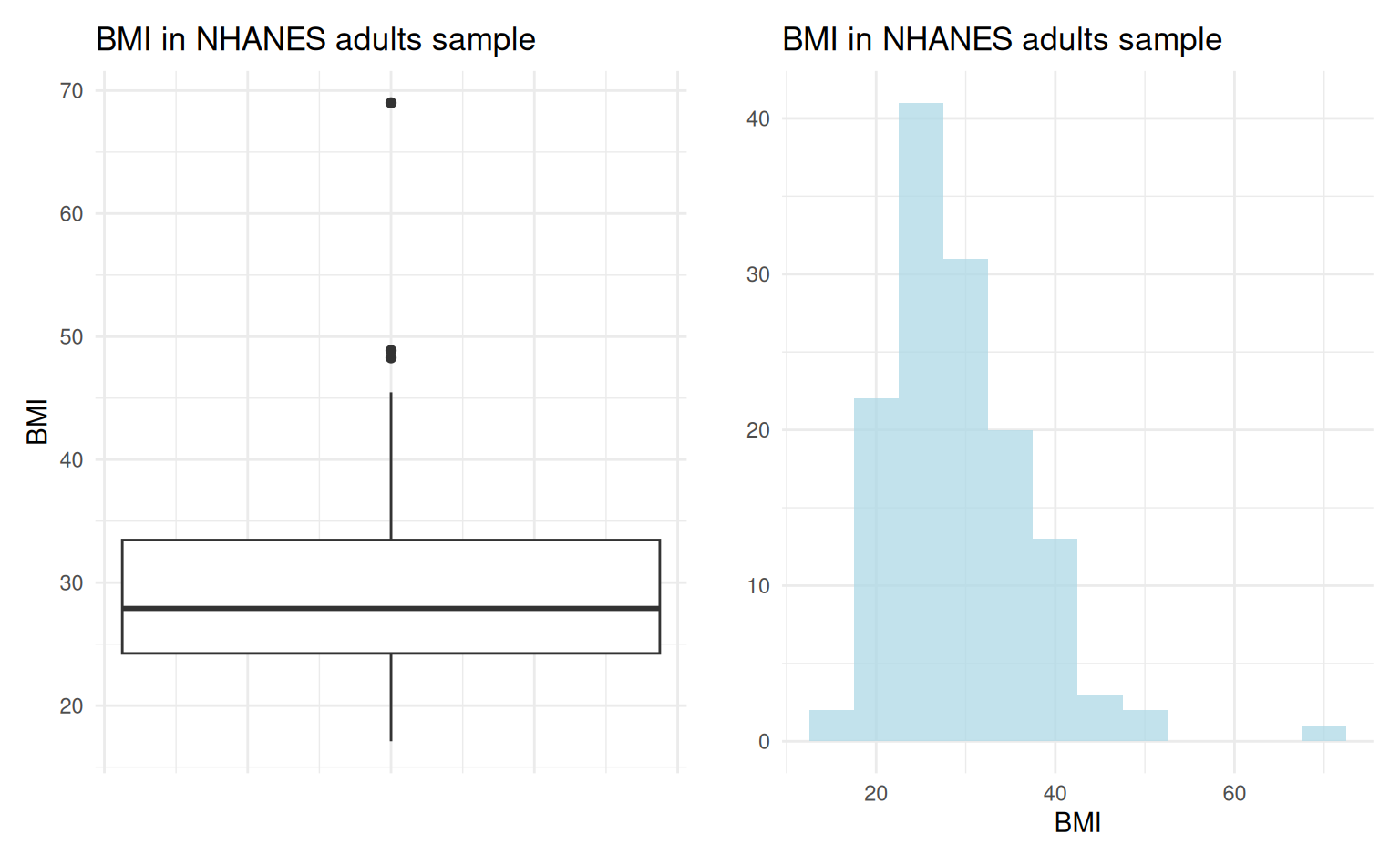
Can we use a 95% confidence interval? Yes!
Confidence interval suggests that population average BMI is well outside the range defined as healthy (BMI of 18.5-24.99):
[1] 27.81388 30.38524
attr(,"conf.level")
[1] 0.95If a (\(1 - \alpha\))(100)% confidence interval for a population mean does not contain a hypothesized value \(\mu_0\), then:
- the observed data contradict the null hypothesis \(H_0: \mu = \mu_0\) (at a given significance level \(\alpha\), e.g., \(\alpha = 0.05\))
- the implied two-sided alternative hypothesis is \(H_A: \mu \neq \mu_0\)
Null and alternative hypotheses
- The null hypothesis (\(H_0\)) posits a distribution for the population reflecting no change from the past, e.g., \(H_0: \mu = \mu_0\).
- The alternative hypothesis (\(H_A\)) claims a “real” difference exists between the distribution of the observed data (a sample) and the distribution implied by the null hypothesis.1
- Since \(H_A\) is an alternative claim, it is often represented by a range of possible parameter values, e.g., \(H_A: \mu \neq \mu_0\).
- A hypothesis test evaluates whether there is evidence against \(H_0\) based on the observed data, using a test statistic.
Framing null and alternative hypotheses
For our BMI inquiry, there are a few possible choices for \(H_0\) and \(H_A\). To simplify and demonstrate, let’s use
- \(H_0: \mu_{\text{BMI}} = 21.7 = \mu_0\), the midpoint of the healthy range
- \(H_A: \mu_{\text{BMI}} > 21.7\)
The form of \(H_A\) above is a one-sided alternative. One could also write a two-sided alternative, \(H_A: \mu_{\text{BMI}} \neq 21.7\).
The choice of one- or two-sided alternative is context-dependent and should be driven by the motivating scientific question.
What’s “real”? The significance level \(\alpha\)
The significance level \(\alpha\) quantifies how rare or unlikely an event must be in order to represent sufficient evidence against \(H_0\).
In other words, it is a bar for the degree of evidence necessary for a difference to be considered as “real” (or significant)1 2.
In the context of decision errors, \(\alpha\) is the probability of committing a Type I error (incorrectly rejecting \(H_0\) when it is true).
Choose (and calculate) a test statistic
The test statistic measures the discrepancy between the observed data and what would be expected if the null hypothesis were true.
When testing hypotheses about a mean, a valid test statistic is \[T = \frac{\bar{X} - \mu_0}{\dfrac{s}{\sqrt{n}}},\] where the test statistic \(T\) follows a \(t\) distribution with \(\nu = n-1\).
The devil is in the details
We will go on to talk about a few more practical versions of the \(t\)-test (e.g., 2-sample \(t\)-test, 1-sample \(t\)-test of paired differences).
In each of these cases, some assumptions are required…
- measurements being compared (e.g., BMI) are randomly (iid) sampled from a normal distribution
- same unknown mean, same unknown variance (plus normality)
Justifying your assumptions is the hardest part
Given the context of your scientific problem, are these assumptions true or reasonable?
Calculate a \(p\)-value…and what is it anyway?
What is the probability that we would observe a result as or more extreme than the observed sample value, if the null hypothesis is true? This probability is the \(p\)-value1.
- Calculate the \(p\)-value associated with the test statistic and then compare it to the pre-specified significance level \(\alpha\).
- A result is considered unusual (or statistically significant) if its associated \(p\)-value is less than \(\alpha\).
Quantifying surprise – the \(S\)-value
Despite their popularity, \(p\)-values are notoriously hard to interpret1. Rafi and Greenland (2020)’s \(S\)-values (“binary surprisal value”) are a cognitive tool for interpreting and understanding \(p\)-values2.
The surprisal value \(S\) for interpreting \(p\)-values
The \(S\)-value is defined via \(p = \left(\frac{1}{2}\right)^s\) as \(s = -\log_2(p)\), where \(p\) is a \(p\)-value.
\(S\) quantifies the degree of surprise associated with experiencing a similar result (as the given \(p\)-value) when evaluating if a coin is fair.
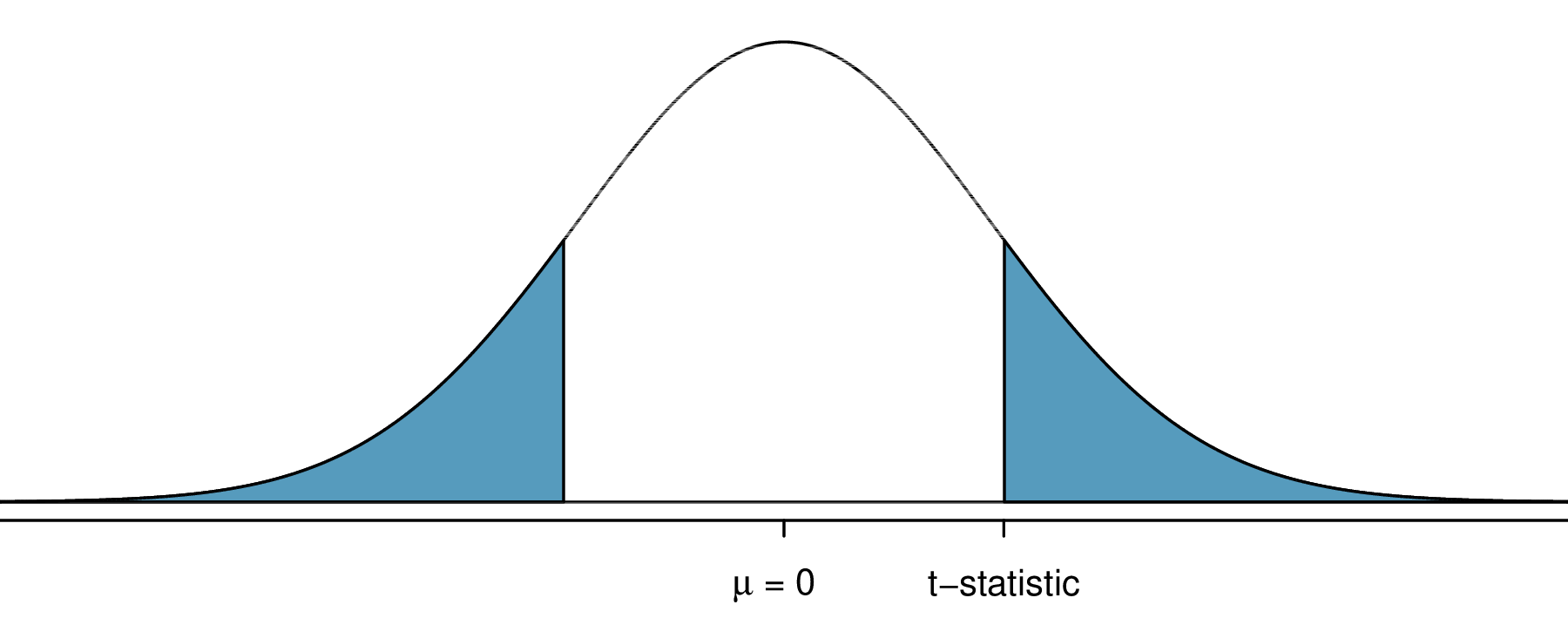
The \(p\)-value for a two-sided alternative
For a two-sided alternative, \(H_A: \mu \neq \mu_0\), the \(p\)-value of a t-test is the total area from both tails of the t distribution that are beyond the absolute value of the observed t statistic:
\[p = 2 \mathbb{P}(T \geq \lvert t \rvert) = \mathbb{P}(T \leq - \lvert t \rvert) + \mathbb{P}(T \geq \lvert t \rvert)\]
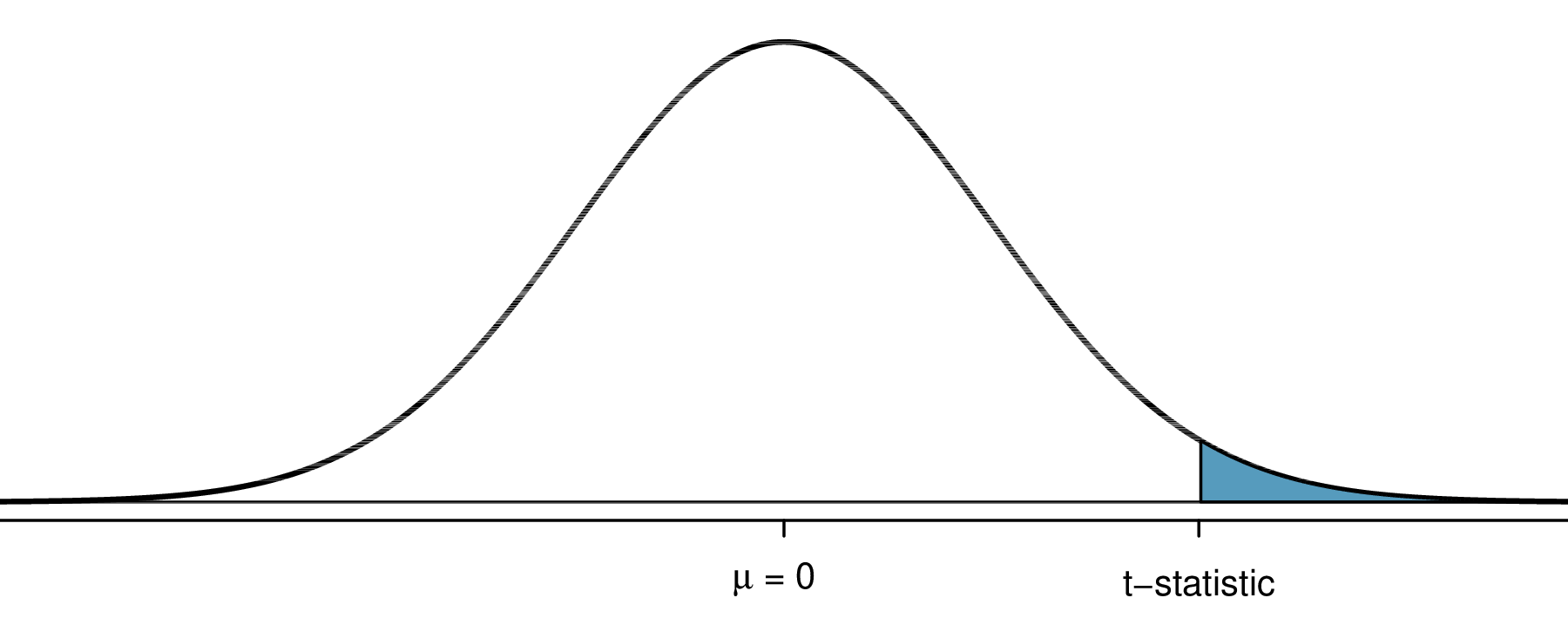
The \(p\)-value for a one-sided alternative
For a one-sided alternative, the \(p\)-value is the area in the tail of the t distribution that matches the direction of the alternative.
For \(H_A: \mu > \mu_0\): \(p = \mathbb{P}(T \geq \lvert t \rvert)\)
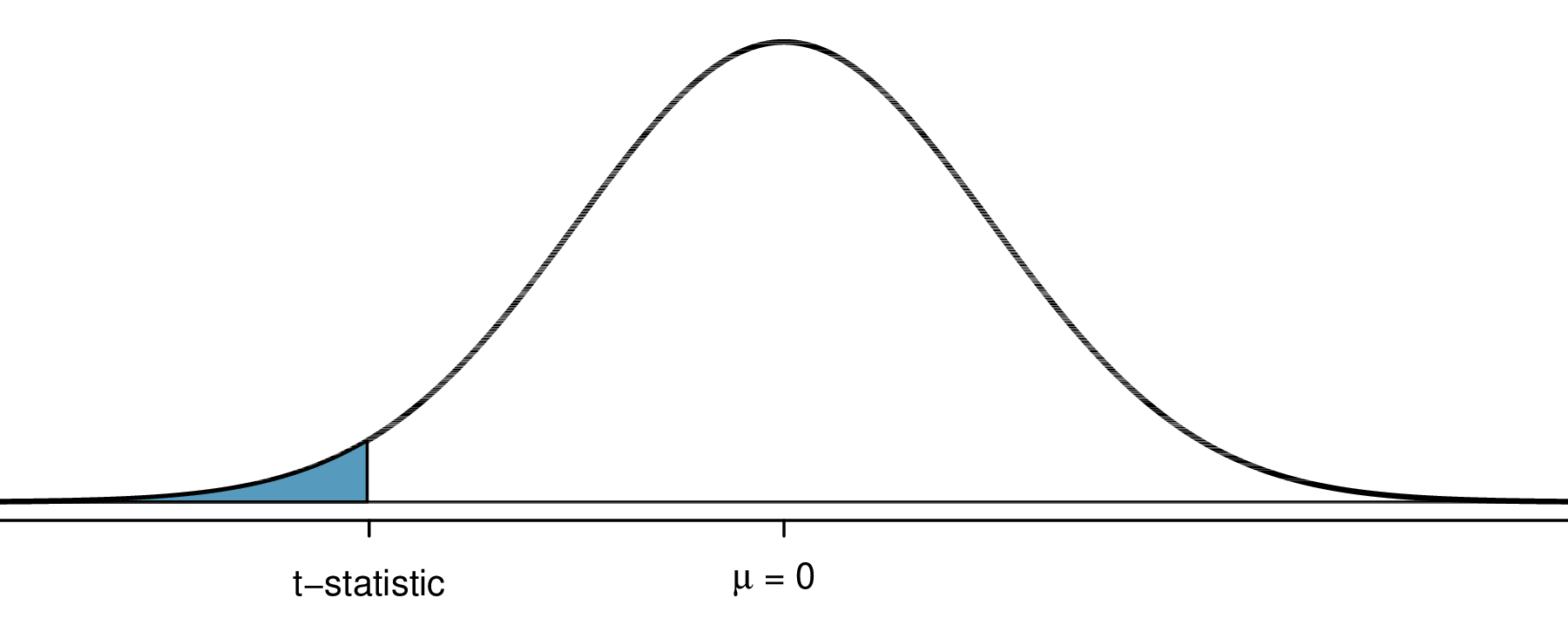
For \(H_A: \mu < \mu_0\): \(p = \mathbb{P}(T \leq - \lvert t \rvert)\)
The \(p\)-value and drawing conclusions
The smaller the \(p\)-value, the stronger the evidence against \(H_0\).
- If the \(p\)-value is as small or smaller than \(\alpha\), we reject \(H_0\); the result is statistically significant at level \(\alpha\).
- If the \(p\)-value is larger than \(\alpha\), we fail to reject1 \(H_0\); the result is not statistically significant at level \(\alpha\)—that is, the evidence we have available does not contradict \(H_0\).
Always state conclusions in the context of the research problem.
Evaluating BMI in the NHANES adult sample
Question: Do Americans tend to be overweight?
One Sample t-test
data: nhanes.samp.adult$BMI
t = 11.383, df = 134, p-value < 2.2e-16
alternative hypothesis: true mean is greater than 21.7
95 percent confidence interval:
28.02288 Inf
sample estimates:
mean of x
29.09956 The Kolmogorov-Smirnov (KS) test
The KS test is a nonparametric test that evaluates the equality of two distributions (n.b., different from testing mean differences).
The empirical cumulative distribution function (eCDF) is \[F_n(x) = \frac{1}{n} \sum_{i=1}^n \mathbb{I}_{(-\infty, x)}(X_i) = \frac{\# \text{ elements} \leq x}{n}\]
The KS test uses as its test statistic \(D_n = \text{sup}_x \lvert F_n(x) - F(x) \rvert\)1, where \(F(x)\) is a theoretical (i.e., assumed) CDF.
Using the KS test: Is BMI normally distributed?
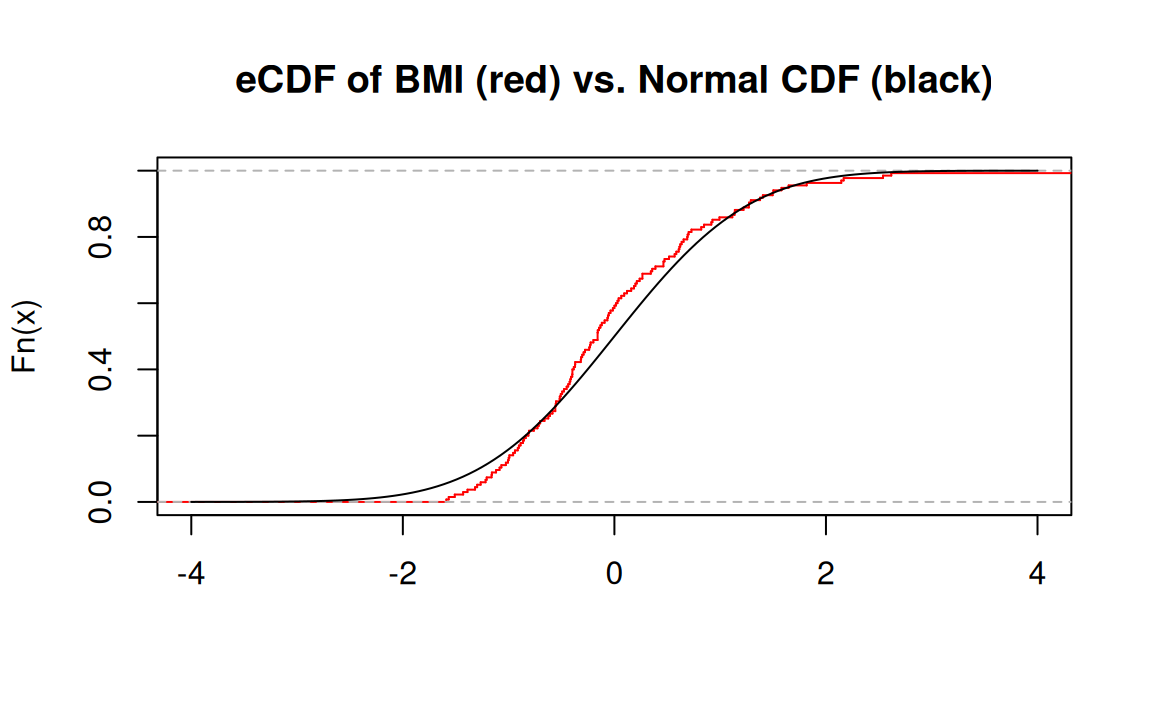
Applying the KS test evaluates evidence against \(H_0\) of BMI (in NHANES population) arising from a normal distribution:
Asymptotic one-sample Kolmogorov-Smirnov test
data: bmi_zstd
D = 0.09895, p-value = 0.1422
alternative hypothesis: two-sidedReferences
Cole, Stephen R, Jessie K Edwards, and Sander Greenland. 2021. “Surprise!” American Journal of Epidemiology 190 (2): 191–93. https://doi.org/10.1093/aje/kwaa136.
Fisher, Ronald Aylmer. 1926. “The Arrangement of Field Experiments.” Journal of the Ministry of Agriculture of Great Britain 33: 503–13.
Freedman, David A, Robert Pisani, and Roger Purves. 2007. Statistics. W. W. Norton & Company.
Mendenhall, William, Robert J Beaver, and Barbara M Beaver. 2012. Introduction to Probability and Statistics. Cengage Learning.
Rafi, Zad, and Sander Greenland. 2020. “Semantic and Cognitive Tools to Aid Statistical Science: Replace Confidence and Significance by Compatibility and Surprise.” BMC Medical Research Methodology 20: 244. https://doi.org/10.1186/s12874-020-01105-9.
Senn, Stephen. 2022. Dicing with Death: Living by Data. Cambridge University Press. https://doi.org/10.1017/9781009000185.
Student. 1908. “The Probable Error of a Mean.” Biometrika 6 (1): 1–25. https://doi.org/10.1093/biomet/6.1.1.
Vu, Julie, and David Harrington. 2020. Introductory Statistics for the Life and Biomedical Sciences. OpenIntro. https://openintro.org/book/biostat.

HST 190: Introduction to Biostatistics