
Introduction to Linear Regression
September 3, 2025
Regression
Regression methods examine the association between a response variable and a set of possible predictor variables (covariates).
- Linear regression posits an approximately linear relationship between the response and predictor variables.
- The response variable \(y\) can be referred to as the dependent variable, and the predictor variable \(x\) the independent variable.
- A simple linear regression model takes the form: \(Y = \beta_0 + \beta_1 X + \epsilon\)
Simple linear regression quantifies how the mean of a response variable \(Y\) varies with a single predictor \(X\), assuming linearity.
Multiple regression
Multiple linear regression evaluates the relationship, assuming linearity, between the mean of a response variable, \(Y\), and a vector of predictors, \(X_1, X_2, \ldots, X_p\), that is, \[ Y = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \cdots + \beta_p X_p + \epsilon \ . \]
This is conceptually similar to the simpler case of evaluating \(Y\)’s mean with respect to a single \(X\), except that the interpretation is much more nuanced (more on this later).
Linearity is an approximation; so, think of regression as projection onto a simpler worldview (“if the phenomenon were linear…”).
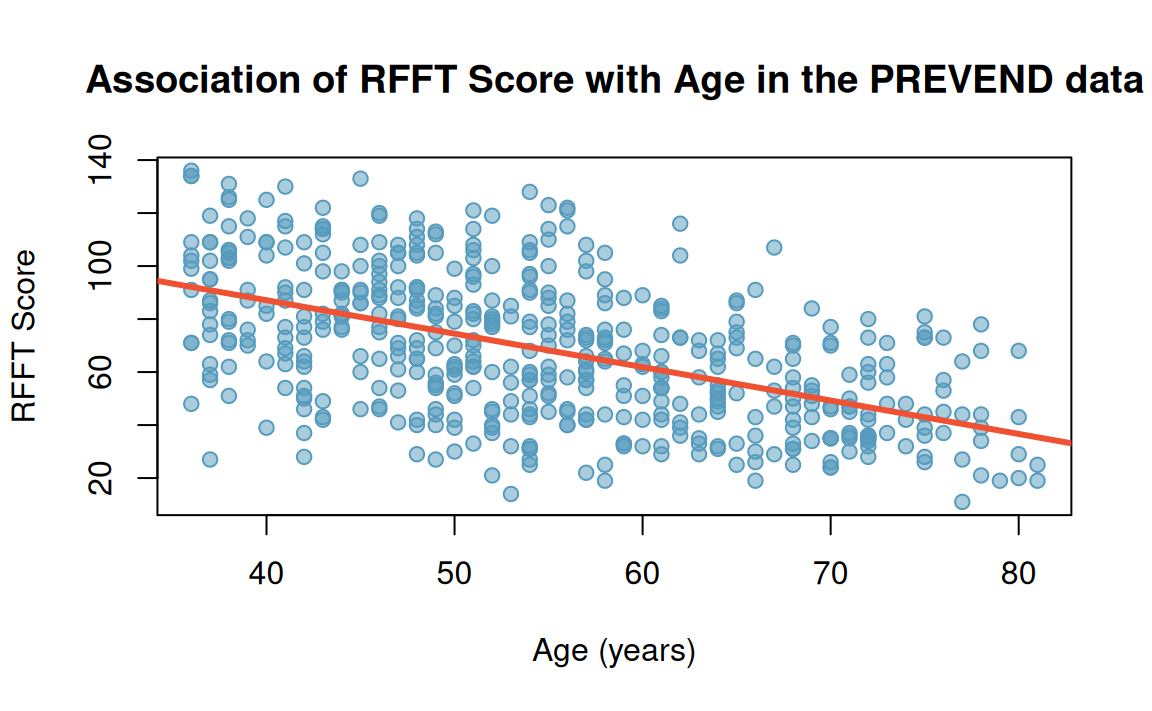
Back to the PREVEND study
As adults age, cognitive function changes over time, largely due to cerebrovascular and neurodegenerative changes. PREVEND study measured clinical, demographic data for participants, 1997-2006.
- Data from 4,095 participants appear the
prevenddataset in theoibiostatRpackage. - Ruff Figural Fluency Test (RFFT) to assess cognitive function (planning and the ability to switch between different tasks).
Assumptions for linear regression
A few assumptions for justifying the use of linear regression to describe how the mean of \(Y\) varies with \(X\).
- Independent observations: \((x,y)\) pairs are independent; that is, values of one pair provide no information on those of others.
- Linearity: \(\E[Y \mid X] = f(X)\) is linear and appears justifiably so in the observed data.
- Constant variability (homoscedasticity): variability of response \(Y\) about the regression line is constant across different values of predictor \(X\).
- Approximate normality of residuals: \(\epsilon \sim \text{N}(0, \sigma^2_{\epsilon})\)
What happens when these assumptions do not hold? 🤔
Linear regression via ordinary least squares
Distance between an observed point \(y_i\) and the corresponding predicted value \(\hat{y}_i\) from the regression line is the residual for the \(i\)th unit.
For \((x_i, y_i)\), where \(\hat{y} = \hat{\beta}_0 + \hat{\beta}_1 x\), the residual \(e_i\) is \(e_i = y_i - \hat{y}_i\)
The least squares regression line minimizes the sum of squared residuals1 \(\sum_{i=1}^n e_i^2\) among \((x_i, y_i) \,\, \forall \,\, i\) to get estimates \((\hat{\beta}_0, \hat{\beta}_1)\).
The mean squared error (MSE), a metric of prediction quality, is also based on the residuals \(\text{MSE} = \frac{1}{n} \sum_{i=1}^n e_i^2\).
Coefficients in least squares linear regression
\(\beta_0\) and \(\beta_1\) are parameters with estimates \(\hat{\beta}_0\) and \(\hat{\beta}_1\); estimates can be calculated from summary statistics:
\(\hat{\beta}_1 = r \dfrac{s_y}{s_x} \qquad \hat{\beta}_0 = \overline{y} - \hat{\beta}_1 \overline{x}\)
- \(\overline{x}\), \(\overline{y}\): sample means of \(x\) and \(y\)
- \(s_x\), \(s_y\): sample SD’s of \(x\) and \(y\)
- \(r\): correlation between \(x\) and \(y\)
Least squares regression line \(\hat{Y} = \hat{\beta}_0 + \hat{\beta}_1 X\) for the association of RFTT and age in the PREVEND data is \(\widehat{\text{RFFT}} = 137.55 -(1.26)(\text{Age})\)
Linear regression: The population view
For a population of ordered pairs \((x, y)\), the population regression line is \(Y = \beta_0 + \beta_1 X + \epsilon\), where \(\epsilon \sim \text{N}(0, \sigma_{\epsilon})\)1.
Since \(\E[\epsilon] = 0\), the regression line is also \(\E[Y \mid x] = \beta_0 + \beta_1 x\), where \(\E[Y \mid x]\) denotes the expectation of \(Y\) when \(X = x\).
So, the regression line is a statement about averages: What do we expect the mean of \(Y\) to be when \(X\) takes on the value \(x\)? If, the mean of \(Y\) follows, in fact, a linear relationship in \((\beta_0, \beta_1)\).
Linear regression: Checking assumptions?
Assumptions of linear regression are independence of study units, linearity (in parameters), constant variability, normality of residuals.
- Independence should be enforced by well-considered study design.
- Other assumptions may be checked empirically…but should we?
- Residual plots: scatterplots in which predicted values are on the \(x\)-axis and residuals are on the \(y\)-axis
- Normal probability plots: theoretical quantiles for a normal versus observed quantiles (of residuals)
Linear regression with categorical predictors
Although the response variable in linear regression is necessarily numerical, the predictor may be either numerical or categorical.
Simple linear regression only accommodates categorical predictor variables with two levels1.
Simple linear regression with a two-level categorical predictor \(X\) compares the means of the two groups defined by \(X\): \[\mathbb{E}[Y \mid X = 1] - \mathbb{E}[Y \mid X = 0] = \beta_0 + \beta_1 - \beta_0 = \beta_1\]
Back to FAMuSS: Comparing ndrm.ch by sex
Let’s re-examine the association between change in non-dominant arm strength after resistance training and sex in the FAMuSS data.
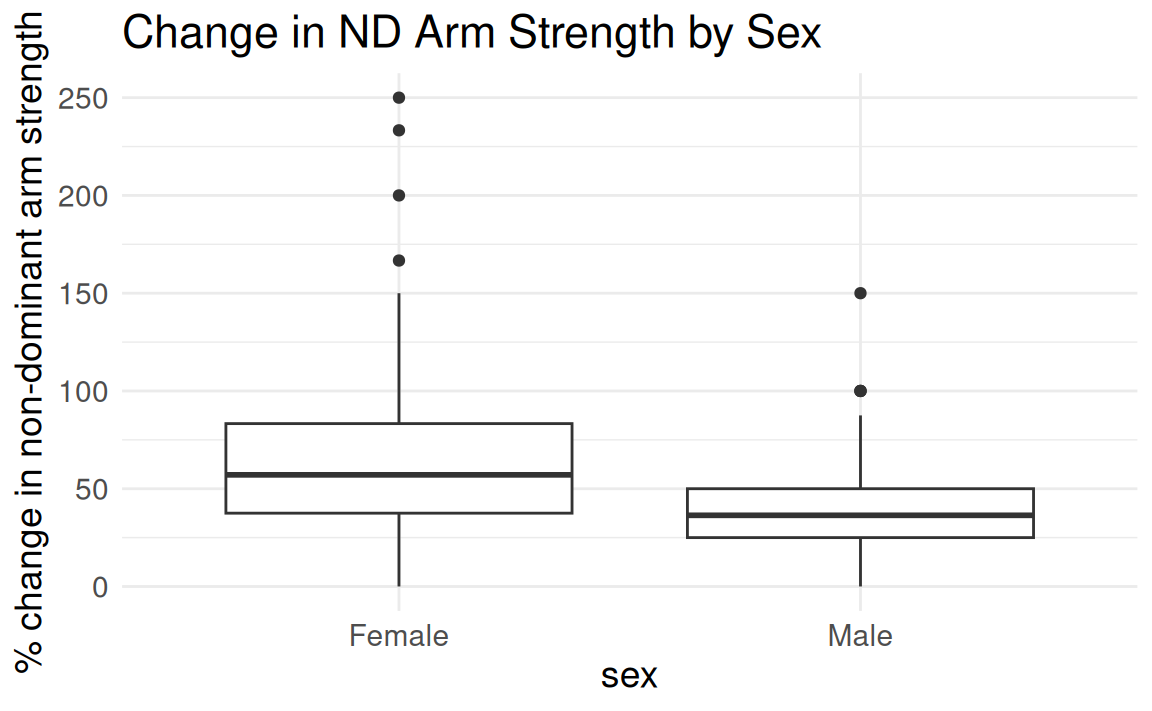
Female Male
62.92720 39.23512 (Intercept) famuss$sexMale
62.92720 -23.69207 \(\widehat{\text{ndrm.ch}} = 62.93 -23.59(\text{sex = male})\)
- Intercept \(\beta_0\): mean in baseline group
- Slope \(\beta_1\): difference of group means
Strength of a regression fit: Using \(R^2\)
- Correlation coefficient \(r\) measures strength of a linear relationship between \((X, Y)\); \(r_{X,Y} = \text{Cov}(X,Y) / \sigma_X \sigma_Y\), is the covariance normalized by the SDs
- \(r^2\) (or \(R^2\)) more common as a measure of the strength of a linear fit, since \(R^2\) describes amount of variation in response \(Y\) explained by the regression fit
\[R^{2} = \dfrac{\text{Var}(\hat{y}_i)}{\text{Var}(y_i)} = \dfrac{\text{Var}(y_i) - \text{Var}(e_i)}{\text{Var}(y_i)} = 1 - \sum_{i=1}^n \dfrac{(y_i - \hat{y}_i)^2}{(y_i - \bar{y})^2}\]
- If a linear regression fit perfectly captured the variability in the observed data, then \(\text{Var}(\hat{y}_i)\) would equal \(\text{Var}(y_i)\) and \(R^2\) would be 1 (its maximum).
- The variability of the residuals about the regression line represents the variability remaining after the fit; \(\text{Var}(e_i)\) is the variability unexplained by the regression fit.
Statistical inference in regression
Assume observed data \((x_i, y_i)\) to have been randomly sampled from a population where the explanatory variable \(X\) and response variable \(Y\) are related as follows \[Y= \beta_0 + \beta_1X + \epsilon, \quad \text{where} \quad \epsilon \sim \text{N}(0, \sigma_{\epsilon}^2)\]
Under this assumption, the slope \(\hat{\beta}_1\) and intercept \(\hat{\beta}_0\) of the fitted regression line are estimates of the parameters \(\beta_0\) and \(\beta_1\).
Goal: Inference for the slope \(\beta_1\), the association1 of \(X\) with \(Y\).
Hypothesis testing in regression
The null hypothesis \(H_0\) is most often about no association:
- \(H_0: \beta_1 = 0\), that is, \(X\) and \(Y\) are not associated
- \(H_A: \beta_1 \neq 0\), that is, \(X\) and \(Y\) variables are associated
Use the \(t\)-test? Recall the \(t\)-statistic (here, with \(df = n - 2\)): \[t = \dfrac{\hat{\beta}_1 - \beta_{1, H_0}}{\text{SE}(\hat{\beta}_1)} = \dfrac{\hat{\beta}_1}{\text{SE}(\hat{\beta}_1)},\] where \(\beta_{1, H_0} = 0\) under the null hypothesis of no association.
Confidence intervals in regression
A \((1-\alpha)\)(100)% confidence interval for \(\beta_1\) is \[\hat{\beta}_1 \pm \left(t^\star \times \text{SE}(\hat{\beta}_1) \right),\] where \(t^\star\) is the appropriate quantile of a \(t\)-distribution, and the standard error1 of the estimator \(\hat{\beta}_1\) is \[\text{SE}(\hat{\beta}) = \sqrt{\dfrac{1}{n-2} \sum_{i=1}^n \dfrac{(y_i - \hat{y}_i)^2}{(x_i - \bar{x})^2}}\]
Example: Linear Regression in an RCT
Consider a randomized controlled trial (RCT) that recruits \(n = 200\) patients, assigns (\(X\)) each to drug or placebo, and monitors them until the trial’s end, at which point an outcome \(Y\) (e.g., a disease severity score) is measured.
| L1 | L2 | X | Y |
|---|---|---|---|
| 1 | 1 | 0 | 1.39 |
| 0 | 0 | 0 | -0.18 |
| 0 | 0 | 0 | -0.20 |
| 1 | 1 | 1 | 3.61 |
The treatment \(X\) is randomized, so it will be balanced on the baseline factors (i.e., confounders \(L_1\), \(L_2\)) on average. Linear regression, \(\mathbb{E}[Y \mid X] = \beta_0 + \beta_1 X\), gives \[\mathbb{E}[Y \mid X = 1] = \beta_0 + \beta_1 \quad \text{and} \quad \mathbb{E}[Y \mid X = 0] = \beta_0,\] the difference of which is \(\mathbb{E}[Y \mid X = 1] - \mathbb{E}[Y \mid X = 0] = \beta_1\)1.
Statistical power and sample size
Question: A collaborator approaches you about this hypothetical RCT, wondering whether \(n=200\) is a sufficient sample size — is it?
In terms of hypothesis testing: \(H_0: \beta_1 = 0\) and \(H_A: \beta_1 > 0\) (the drug “works”). How large does \(\beta_1\) have to be for it to be detectable? Is \(n=200\) enough?
The power of a statistical test is the probability that the test (correctly) rejects the null hypothesis \(H_0\) when the alternative hypothesis \(H_A\) is true. Power depends on…
- the hypothesized effect size (\(\beta_1\) in an RCT – but not generally)
- the variance of each of the two groups (i.e., \(\sigma_1\), \(\sigma_2\) for treatment, placebo)
- the sample sizes of each of the two group (\(n_1\), \(n_2\))
Outcomes and errors in testing
| Result of test | ||
|---|---|---|
| State of nature | Reject \(H_0\) | Fail to reject \(H_0\) |
| \(H_0\) is true | Type I error, \(\mathbb{P} = \alpha\) (false positive) | No error, \(\mathbb{P} = 1 - \alpha\) (true negative) |
| \(H_A\) is true | No error, \(\mathbb{P} = 1 - \beta\) (true positive) | Type II error, \(\mathbb{P} = \beta\) (false negative) |
Choosing the right sample size
Study design includes calculating a study size (sample size) such that probability of rejecting \(H_0\) is acceptably large, typically 80%-90%.
It is important to have a precise estimate of an appropriate study size, since
- a study needs to be large enough to allow for sufficient power to detect a difference between groups when one exists, but
- not so unnecessarily large that it is cost-prohibitive or unethical.
Often, simulation is a quick and feasible way to conduct a power analysis.
Multiple regression
In most practical settings, more than one explanatory variable is likely to be associated with a response.
Multiple linear regression evaluates the relationship between a response \(Y\) and several (say, \(p\)) predictors \(X_1, X_2, \dots, X_p\).
Multiple linear regression takes the form \[Y = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \cdots + \beta_p X_p + \epsilon\]
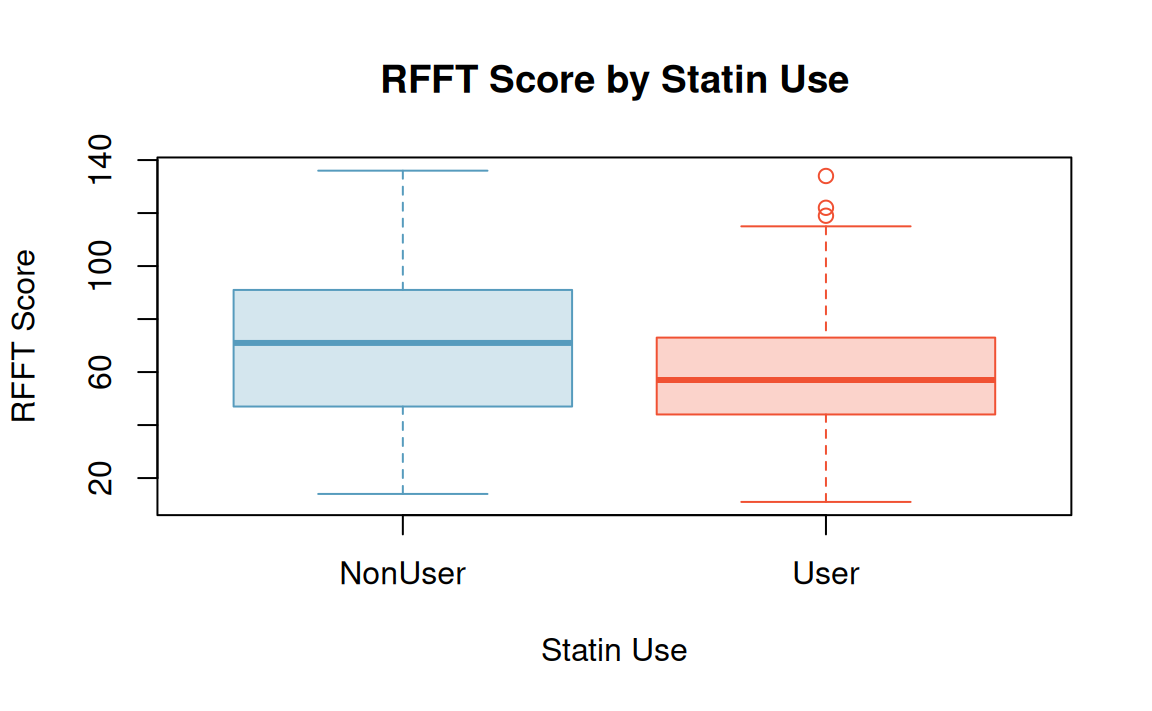
PREVEND: Statin use and cognitive function
The PREVEND study collected data on statin use and demographic factors.
- Statins are a class of drugs widely used to lower cholesterol.
- Recent guidelines for prescribing statins suggest statin use for almost half of Americans 40-75 years old, as well as nearly all men over 60.
- A few small (low \(n\)) studies have found evidence of a negative association between statin use and cognitive ability.
Age, statin use, and RFFT score
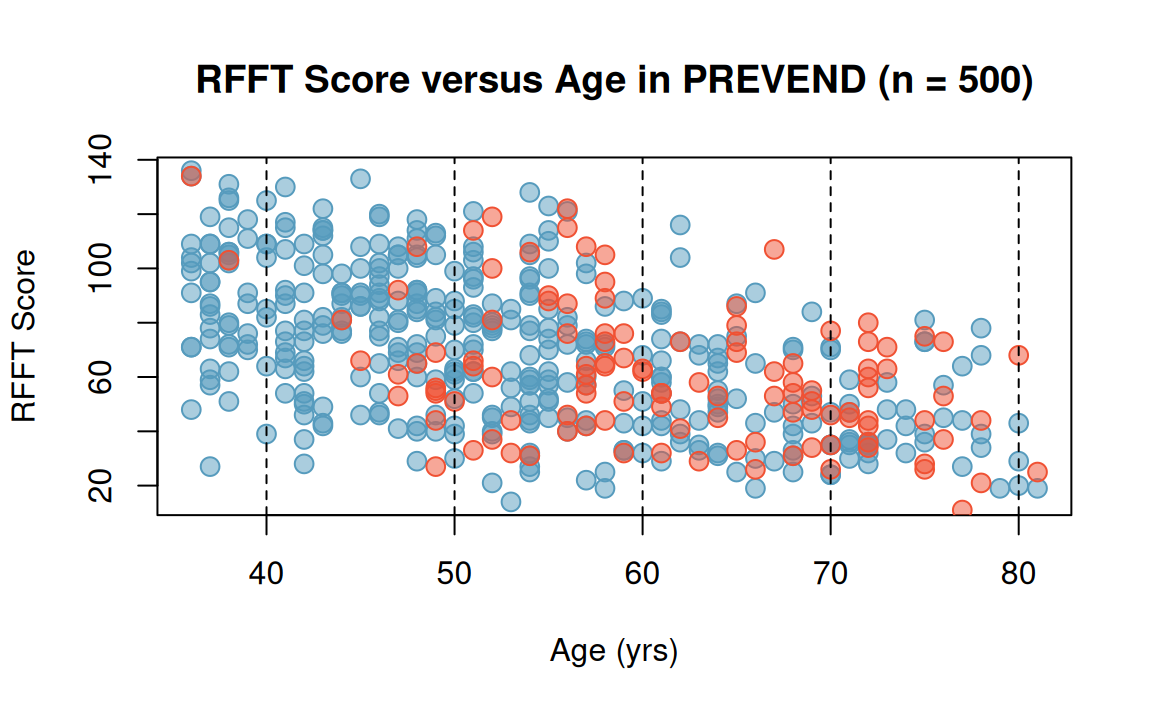
Red dots represent statin users; blue dots represent non-users.
Call:
lm(formula = RFFT ~ Statin, data = prevend.samp)
Coefficients:
(Intercept) StatinUser
70.71 -10.05 Interpretation of regression coefficients
Multiple (linear) regression takes the form \[Y = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \cdots + \beta_p X_p + \epsilon,\] where \(p\) is the number of predictors (or covariates).
Recall the correspondence of the regression equation with \[\mathbb{E}[Y \mid X_1, \cdots, X_p] = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \cdots + \beta_p X_p,\]
The coefficient \(\beta_j\) of \(X_j\): the predicted difference in the mean of \(Y\) for groups that differ by one unit in \(X_j\) and for whom all other predictors take on the same value.
Practically, a coefficient \(\beta_j\) in multiple regression is the association between the response \(Y\) and predictor \(X_j\), after adjusting for other predictors \(X_i: i = 1, \cdots, p \lvert i \neq j\).
In action: RFFT vs. statin use and age
Fit the multiple regression with lm():
# fit the linear model
prevend_multreg <- lm(RFFT ~ Statin + Age, data = prevend.samp)
prevend_multreg
Call:
lm(formula = RFFT ~ Statin + Age, data = prevend.samp)
Coefficients:
(Intercept) StatinUser Age
137.8822 0.8509 -1.2710 \(\beta_{\text{statin}} =\) 0.851 — so it seems statin use is associated with a positive difference in RFTT, when adjusting for age (i.e., for study units in the same age range).
Assumptions for multiple regression
Analogous to those of simple linear regression…
- Independence: units \((y_i, x_{1,i}, x_{2,i}, \dots, x_{p, i})\) independent in \(i\).
- Linearity: for each predictor variable \(x_j\), difference in the predictor is linearly related to difference in the response variable in groups defined by all other predictors taking on the same value.
- Constant variability: \(\epsilon\) have approximately constant variance.
- Normality of residuals: \(\epsilon\) approximately normally distributed.
References
Tsiatis, Anastasios A, Marie Davidian, Min Zhang, and Xiaomin Lu. 2008. “Covariate Adjustment for Two-Sample Treatment Comparisons in Randomized Clinical Trials: A Principled yet Flexible Approach.” Statistics in Medicine 27 (23): 4658–77. https://doi.org/10.1002/sim.3113.

HST 190: Introduction to Biostatistics